【深度学习】学习率 (learning rate)
”学习率 (learning rate)“ 的搜索结果
1. 什么是学习率(Learning rate)? 学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛...
《TensorFlow实战Google深度学习框架(第2版)》4.3 节介绍了在训练神经网络时, 需要设置学习率( learning rate )控制参数更新的速度。 本节将进一步介绍如何设置学习率。学习率决定了参数每次更新的幅度。 如果...
学习率下降 Pytorch实现学习率下降。 论文链接: : 为Cifar10训练ResNet-34: 跑: python main.py --model=resnet --optim=adam_lrd --lr=0.001 --LRD_p=0.5 python main.py --model=resnet --optim=adam --lr...
对于刚刚接触深度学习的的童鞋来说,对学习率只有一个很基础的认知,当学习率过大的时候会导致模型难以收敛,过小的时候会收敛速度过慢,但其实学习率是一个十分重要的参数,合理的学习率才能让模型收敛到最小点而非...
在深度学习中,学习率(Learning Rate)是指模型在每次迭代中更新参数的幅度大小,学习率衰减(Learning Rate Decay)则是指在训练过程中逐渐降低学习率的过程。通过学习率衰减,可以使模型在训练后期更加稳定地收敛...
如下图,蓝色曲线表示mini-batch梯度下降,绿色曲线表示采用学习率衰减的梯度下降。mini-batch梯度下降最终会在最小值附近的区间摆动(噪声很大),不会。随着学习率的衰减,步长会逐渐变小,因此最终。为了更加近似...

权重衰减(weight decay)与学习率衰减(learning rate decay)
PyTorch可视化动态调整学习率lr_scheduler:https://blog.csdn.net/ayiya_Oese/article/details/120704261。

Introduction学习率 (learning rate),控制 模型的 学习进度 : 学习率大小 学习率 大学习率 小学习速度快慢使用时间点刚开始训练时一定轮数过后副作用1.易损失值爆炸;2.易振荡。1.易过拟合;2.收敛速度慢。...
步长(学习率) 在进行梯度下降法的过程中,我们需要通过调整η\etaη学习率的值来调整参数每次要走的距离。适当的调整η\etaη可以更准确的找到LLL的最小值以及参数值。 下面需要注意调整步长η\etaη(往下一步要走...
深度学习: 学习率 (learning rate) 作者:liulina603 致敬 原文:https://blog.csdn.net/liulina603/article/details/80604385 深度学习: 学习率 (learning rate) Introduction 学习...
本文从梯度学习算法的角度中看学习率对于学习算法性能的影响,以及介绍如何调整学习率的一般经验和技巧。 在机器学习中,监督式学习(Supervised Learning)通过定义一个模型,并根据训练集上的数据估计最优参数...

本文从梯度学习算法的角度中看学习率对于学习算法性能的影响,以及介绍如何调整学习率的一般经验和技巧。在机器学习中,监督式学习(Supervised Learning)通过定...
1. 什么是学习率 调参的第一步是知道这个参数是什么,它的变化对模型有什么影响。 (1)要理解学习率是什么,首先得弄明白神经网络参数更新的机制-梯度下降+反向传播。参考资料:...
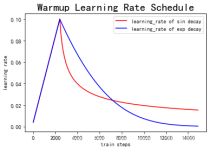


文章目录分段常数衰减 tf.train.piecewise_constan...在使用优化算法的时候,我们都需要设置一个学习率(learning rate)。我这里总结了一些博主的方法。 学习率 的设置在训练模型的时候也是非常重要的,因为学习率...
TensorFlow 学习率 learning rate的设置:指数衰减法。函数:tr.train.exponential_decay 初始时使用较大的学习率较快地得到较优解,随着迭代学习率呈指数逐渐减小。 decayed_learning_rate = learning_rate*...

“微信公众号”1. 权重衰减(weight decay)L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。1.1 L2正则化与权重衰减系数L2正则化就是在代价函数后面再...

Adaptive Learning Rate 一、问题描述 当分析训练的loss已经不会随着gradient的更新而变化时,不一定就是local minima或者saddle point,分析norm of gradient ,发现在loss几乎不变的时候,gradient 还在保持着较...
learning−rate=min(learning−rate)+[max(learning−rate)−min(learning−rate)]∗eiterationdecay−speedlearning-rate=min(learning-rate)+[max(learning-rate)-min(learning-rate)]*e^{\frac{iteration}{decay-...

由于种种原因, 需要自己写一个lr_scheduler, 目前主流的方法是从optimizer中获取, 代码如下: optimizer.state_dict()['param_groups'][0]['lr']
推荐文章
- 我是如何通过一个 XSS 探测搜狐内网扫描内网并且蠕动前台到最后被发现的-程序员宅基地
- 基于Java+SpringMvc+Vue求职招聘系统详细设计实现_springmvc的互联网招聘求职系统-程序员宅基地
- C语言之进制转换_c语言进制转换-程序员宅基地
- html+css知识点全面总结(三)_html里的css里的step-程序员宅基地
- Java琐碎知识点_分布式定时任务的特点-程序员宅基地
- Mysql——入门_mysql用户性别范围0-120-程序员宅基地
- Python爬虫史上超详细讲解(零基础入门,老年人都看的懂)-程序员宅基地
- Linux 任务调度_sched_nice-程序员宅基地
- Scipy库提供了多种正态性检验和假设检验方法_scipy shapiro-wilk 统计量-程序员宅基地
- 彻底搞懂 python 中文乱码问题_py乱码-程序员宅基地